

免费流量哪里来:搜索引擎的工作原理
网络水军不可靠,流量获取要走正道!
在上一章的内容里,我们明确了 SEO 的定位,阐释了企业仍然需要重视 SEO 策略的原因。
本章,我们将带你全面了解搜索引擎的工作原理,包括内容爬取、算法排序、惩罚手段等等,学习如何排除多余的干扰因素,准确拿捏直接影响内容流量和点击的关键,最终实现“低成本,高流量”的营销目标!
简单来说,搜索引擎的工作原理可以概括为以下几个步骤:
- 网络爬虫(Spider)
- 网页索引(Indexing)
- 搜索算法(Search algorithm)
- 搜索结果呈现(Search results presentation)
我们一步一步拆开来详解。
搜索引擎如何获得你的内容
搜索引擎通过网络爬虫程序,能够自动访问互联网上的网页并抓取网页内容。
爬虫程序会按照一定的算法和规则,从一个网页中发现并提取出链接,再继续爬取链接指向的网页,形成一个不断扩大的网页集合,这就是所谓的网络爬虫。
以百度为例:百度有个程序叫“百度蜘蛛”,会对网络上的海量页面进行爬取,之后会根据爬取的结果进行预处理,接着进行排名。
所以当企业做好自己的网站后,一般都希望“蜘蛛”来爬取,而且蜘蛛来的次数越多越好。
当爬虫获得了网页的内容后,搜索引擎就会将抓取到的内容进行处理,并将处理后的结果保存在索引数据库中。
索引数据库通常是一个庞大的、高效的关系型数据库,它包含了网页内容的关键信息,如标题、关键字、描述、链接等等。
而建立索引的主要目的,是为了帮助程序进行快速查找,因为搜索引擎在匹配结果时并不是直接在互联网上进行搜索,而是在搜索它们已经储存的网页索引。
用更通俗的方式来类比的话,上述过程可以简单理解为:
搜索引擎就是个巨大的图书馆,爬虫就是从世界各地搜罗图书的过程,而索引就是给这些图书按类别打上标签,方便前来找书的人查找。
搜索引擎的算法排序
现在,图书馆里的书有了,索引标签也有了,当用户前来找书的时候,该用什么方式展现给他呢?总不能把所有的书往他面前一扔,说:“你要的就在这里面,具体要哪一本你自己找吧。”
因此,当用户在搜索引擎中输入关键词时,搜索引擎会根据搜索算法,从索引数据库中匹配相关的网页,并按照相关性排序后,将搜索结果呈现给用户。
划重点:搜索算法是搜索引擎的核心,通常会考虑多个因素来计算一个网站的相关性。具体见下表:

注:部分释义来自互联网如果仍然用图书馆来类比的话,可以理解为:影响一本书摆放的位置,跟这本书的封面设计、内容质量、口碑热度、作者知名度等一系列因素都有关系。

简单总结一下,搜索引擎的原理可简单概括为:
搜索引擎通过爬虫程序获得网站内容并建立索引,再通过一套复杂的算法给网站排序,最终呈现给用户包括网页的标题、摘要和链接等信息的搜索结果。
所以,想要提升网站在搜索结果中的排名,就要在影响算法排序的各种因素上多下些功夫,具体怎么做呢?可以期待我们之后的内容——站内优化:搜索引擎喜欢的网站是什么样的。
而现在,我们先要聊一个严肃的话题:有哪些提升排名的手段是绝对不可取的,同时,搜索引擎会给采用作弊手段的网站给予什么样的惩罚?
搜索引擎的作弊与惩罚手段
事先声明:这一部分的内容绝不是鼓励采用作弊方法来优化网站排名,而是希望广大读者能够引以为戒,不要做出有损企业品牌形象的违规行为!
一般来说,常见的作弊手段有如下几种:
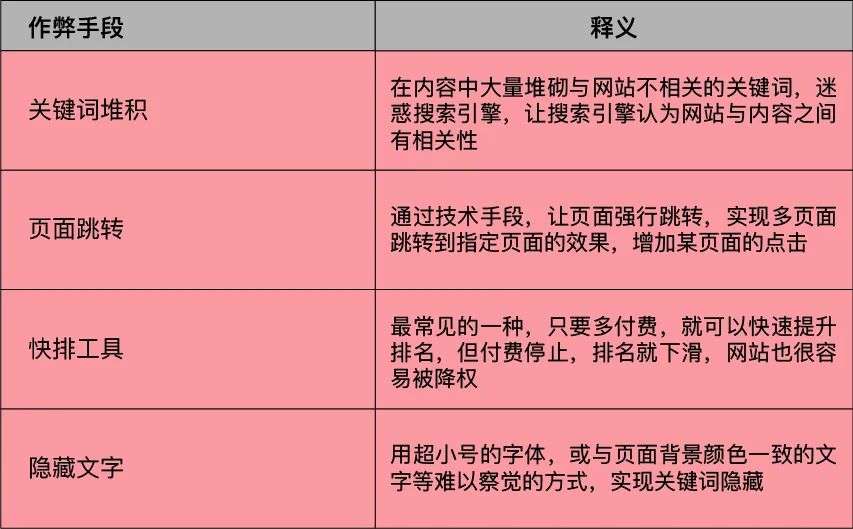
那么,一旦采用了上述作弊手段,并被搜索引擎发现,将会面临什么样的后果呢?
举个例子:近期,我们在查阅同行数据时,发现某网站的权重忽然降到了0,关键词收录也从之前的几百个降至十几个,移动端关键词收录甚至降到了个位数。
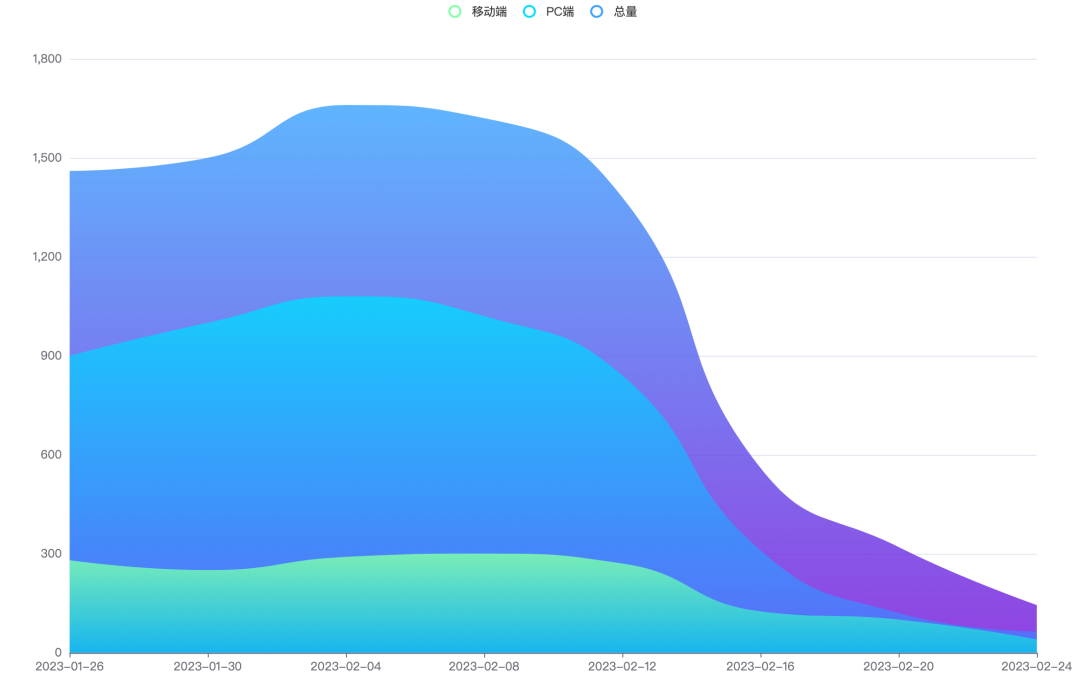
这意味着:该网站可能采用了一些违规优化的手段,被搜索引擎发现并降权处罚。
未来很长一段时间里,用户搜索行业相关产品的时候,该网站都无法在首页显示。这会使得企业失去大量来自搜索引擎的流量来源,对业务增长的影响是非常严重的。
或许有人会抱着侥幸心理:只要不被发现,不就没事了吗?
不好意思,为了对付这些作弊手段,搜索引擎也增加了非常强大的应对措施。以百度为例,为打击SEO作弊,百度推出了极具针对性的反作弊算法,来识别这些不道德行为:
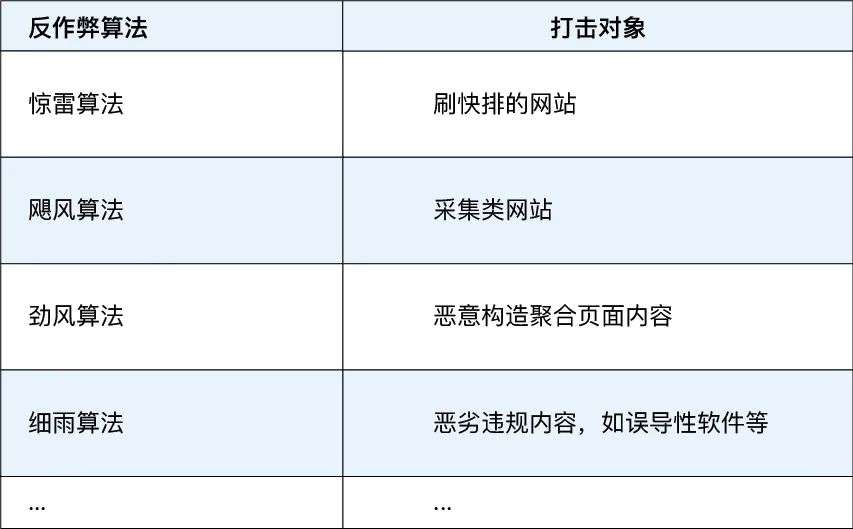
所以,SEOer 一定要记住:优化手段千千万,千万别碰违规款,有朝一日被发现,所有辛苦一场空!
下期预告
搞清楚了搜索引擎的工作原理,我们就要正式开始有针对性的优化自己的网站了。
下一章我们将为你解答:一套完整的 SEO 的流程是怎样的?我该如何用正当手段,在尽可能低的成本范围内,将我的网站优化成搜索引擎“喜欢”的样子?









